© Andrii Shyp / Alamy Stock Vector
Diving into the mechanics of how deep neural networks (DNNs) are trained in machine learning, KAUST researchers have clarified a key discrepancy between the theory and practice of training on distributed computing platforms.
As artificial intelligence algorithms become more sophisticated and capable in their decision-making ability, the DNNs at their heart become increasingly onerous to train. Training DNNs requires enormous volumes of data and is a computationally intensive task that often relies on parallel processing across many distributed computers. However, this type of distributed computing demands a huge amount of data transfer between the parallel processes, and the actual speed up remains far from optimal.
Making distributed deep learning more efficient by reducing the amount of data that needs to be shared among computational nodes is one of the hottest topics in machine learning. Aritra Dutta, Panos Kalnis and their colleagues in the Extreme Computing Research Center have been working at the interface between distributed systems and machine learning to tackle just such problems.
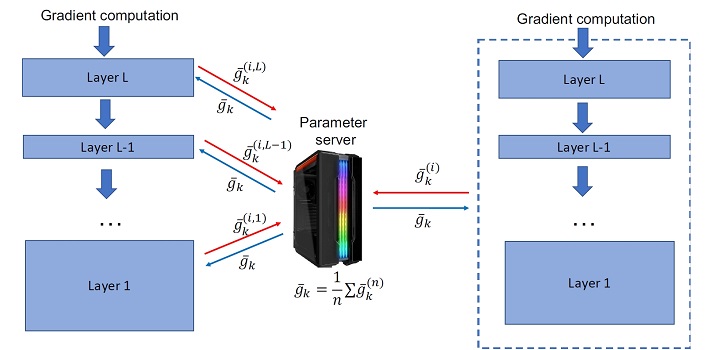
“We have been working on implementing a uniform framework for compression methods for distributed deep learning for some time,” says Dutta. “However, there are daunting challenges to implement such a framework. The first step in this research has been to close a fundamental knowledge gap between theory and practice; that existing compressed communication methods assume that the compression operators are applied to the entire model, when popular distributed machine learning toolkits perform compression layer by layer.”
Read the full article
Related Persons


