Peter Wonka's new query tool, called a relation-augmented image descriptor will change forever querying images online.
Today, querying the massive amounts of images available in online databases such as Instagram can be a time-consuming experience. Researchers from the King Abdullah University of Science and Technology (KAUST) and the University College London, have developed a new tool that generates image queries based on a geometric description of objects in spatial relationships with potential applications in computer graphics, computer vision and automated object classification.
About
Today, querying the massive amounts of images available in online databases such as Flickr and Instagram can be a time-consuming experience and sometimes even ineffective. Researchers from the King Abdullah University of Science and Technology (KAUST), Saudi Arabia, and the University College London, have developed a new tool that generates image queries based on a geometric description of objects in spatial relationships with potential applications in computer graphics, computer vision, and automated object classification.
The collection of photographs and pictures available on the internet represents an immense source of data that can be "read" and used only if we use queries capable of sorting out images according to their salient attributes.
"At present, when searching for images on the internet, the query is based entirely on text descriptions that go along with them," says Peter Wonka, the researcher from KAUST who designed and led the study. "For being effective a text description needs to be short and to provide true and pertinent information on the picture it represents."
Wonka and his colleagues Paul Guerrero and Niloy Mitra from University College London decided to add something more powerful to the text-based search tool currently available.
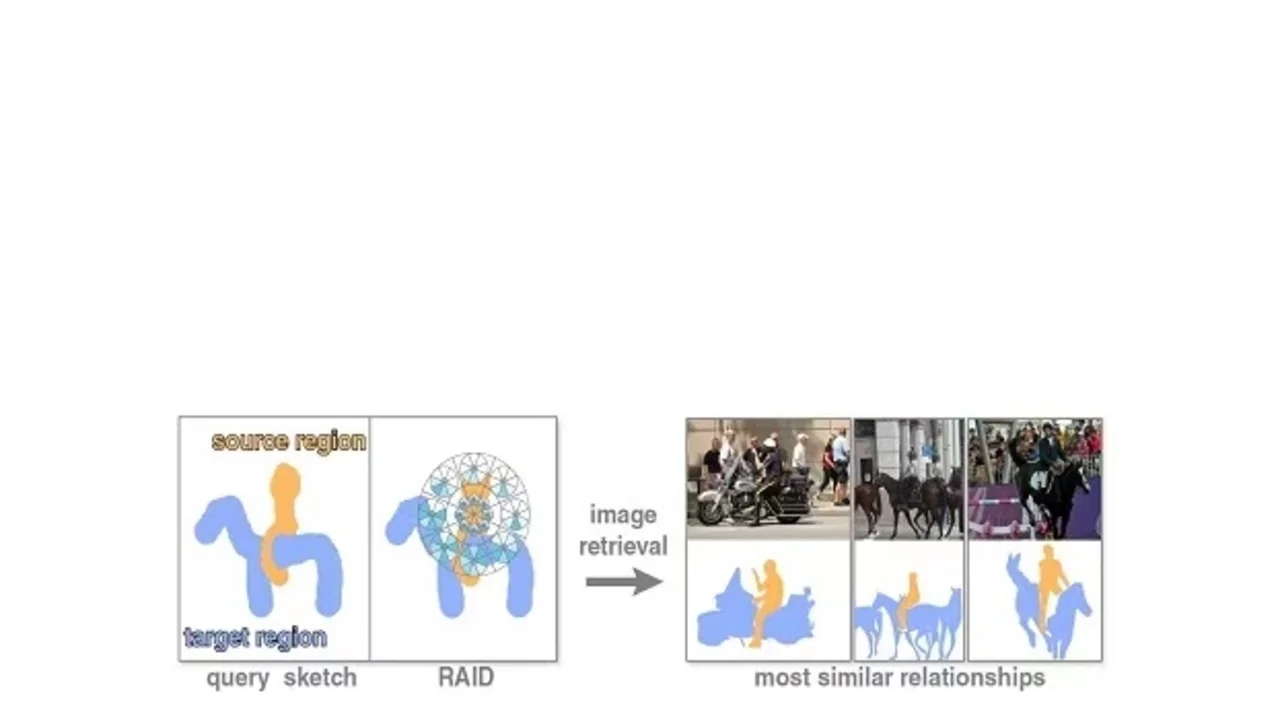
"The obstacle was defining an extra descriptor without adding extra metadata to existing images", explained Wonka " and we went for indicators of existing relationships between objects-such as 'riding,' 'carrying,' 'holding' or 'standing on'. In other words, we added verbs to the nouns describing the images."
The new query tool called a relation-augmented image descriptor (RAID) is able to analyze the textual description while searching for matches using geometric analogies.
"RAID allows queries using complete textual descriptions such as 'a person standing on snowboard' as well as images or simple sketches of the desired composition of objects," said Wonka. "The new tool uses spatial descriptors such as 'above' or 'left of' - which allow discriminating among different complex relationships."
The team is currently working on a three-dimensional version of the descriptor able to search for extra details in the pictures.
