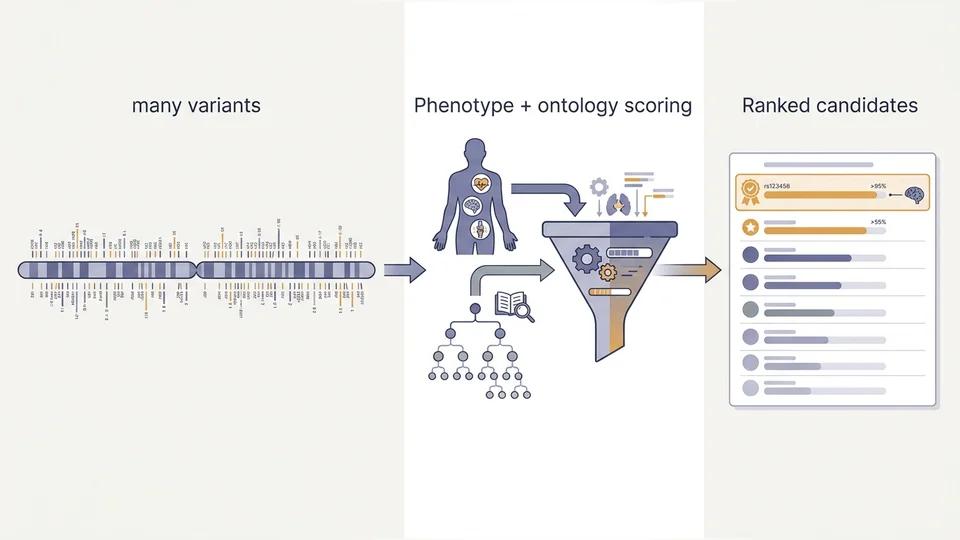
About Ashraf M. Kibriya Ashraf M. Kibriya Postdoctoral Research Fellow (former), Computer, Electrical and Mathematical Sciences and Engineering big data machine learning Research Interests My research interests include the application of Big Data and Machine Learning techniques to real-world problems in various domains, including biology and biomedicine. In particular, I'm interested in Deep Learning, Text Mining, Network Analysis and Graph Mining. Professional Profile 2018-Present: Postdoctoral Fellow, KAUST, Thuwal, Saudi Arabia 2011-2018: Doctoral Fellow, KU Leuven, Belgium 2010-2011: Pre-doctoral fellow, KU Leuven, Belgium 2007-2009: Database developer / Datamining specialist, Datamine Ltd., New Zealand 2002-2005: Research Programmer, Machine Learning Projects Related Projects 2019 CompleX: Variant Prioritization in Complex Disease Tue, Jan 1 2019 - Fri, Dec 31 2021 Applied Ontology Neuro-Symbolic AI Rare disease Semantic similarity The hardest cases in clinical genome sequencing are the ones where no single variant explains the disease. As Mendelian gene discovery slows and the diagnostic rate for whole-exome sequencing stalls below 50%, growing evidence points to oligogenic and polygenic origins: combinations of medium-rare or common alleles that, individually, look unremarkable. Population-level approaches lack the power to find them, and traditional single-gene Mendelian reasoning ignores them. The CompleX project (2019–2021, with the Universities of Cambridge and Birmingham) set out to break this impasse by extending
CompleX: Variant Prioritization in Complex Disease Tue, Jan 1 2019 - Fri, Dec 31 2021 Applied Ontology Neuro-Symbolic AI Rare disease Semantic similarity The hardest cases in clinical genome sequencing are the ones where no single variant explains the disease. As Mendelian gene discovery slows and the diagnostic rate for whole-exome sequencing stalls below 50%, growing evidence points to oligogenic and polygenic origins: combinations of medium-rare or common alleles that, individually, look unremarkable. Population-level approaches lack the power to find them, and traditional single-gene Mendelian reasoning ignores them. The CompleX project (2019–2021, with the Universities of Cambridge and Birmingham) set out to break this impasse by extending