Abstract
What if we have been oversolving in computational science and engineering for decades? Are low precision arithmetic formats only for AI workloads? How can HPC applications exploit mixed-precision hardware features? This BoF invites the HPC community at large interested in applying mixed precisions into their workflows and discussing the impact on time-to-solution, memory footprint, data motion, and energy consumption. Experts from scientific applications/software libraries/hardware architectures will briefly provide the context on this trendy topic, share their own perspectives, and mostly engage with the audience via a set of questions, while gathering feedback to define a roadmap moving forward.

Context
Motivated by the quickly changing hardware landscape, which nowadays is prominently equipped in low-precision arithmetic support, mixing floating-point precision formats has become a mainstream algorithmic optimization. The trade-offs are also important to consider and are not immediately obvious. These optimizations require support from the usual software stack (libraries, middleware, and application codes), strong numerical validation procedures, and ultimately scientific evidence that the applications’ key results survived the intermediate precision loss.

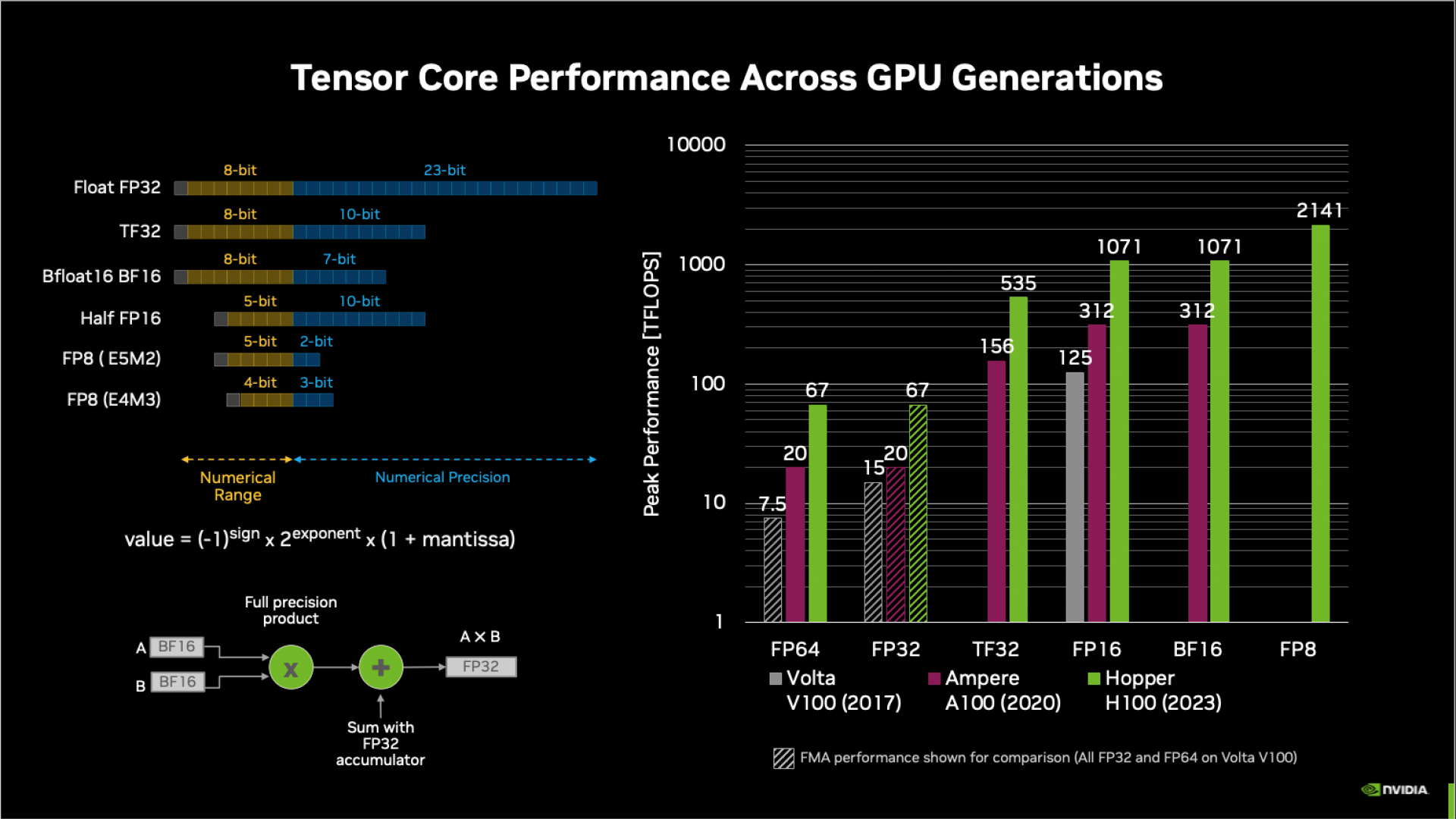
The emphasis on alternatives to the IEEE 754 floating-point standard, emerged in recent years due to machine learning’s insatiable need for computational power to train deep models composed of convolutional neural networks or ever growing transformer models based on attention mechanism for natural language processing or human-level models that play open-ended games such as Go, DOTA 2, and Poker or predict structural properties of folded proteins (recall AlphaGo, AlphaZero, or AlphaFold). A successful training session for these models requires in excess of Peta-FLOPS per day and costs millions of dollars due their hardware and energy requirements. To reduce the power draw, drastic reduction in floating-point storage bits is required to reap energy-saving benefits in addition to other tricks-of-the-trade such as sparsification and related approaches based on lottery ticket hypothesis. These were the driving factors towards lower-precision representations and specialized tensor FP units that enable Peta-FLOPS level performance from a single compute node.
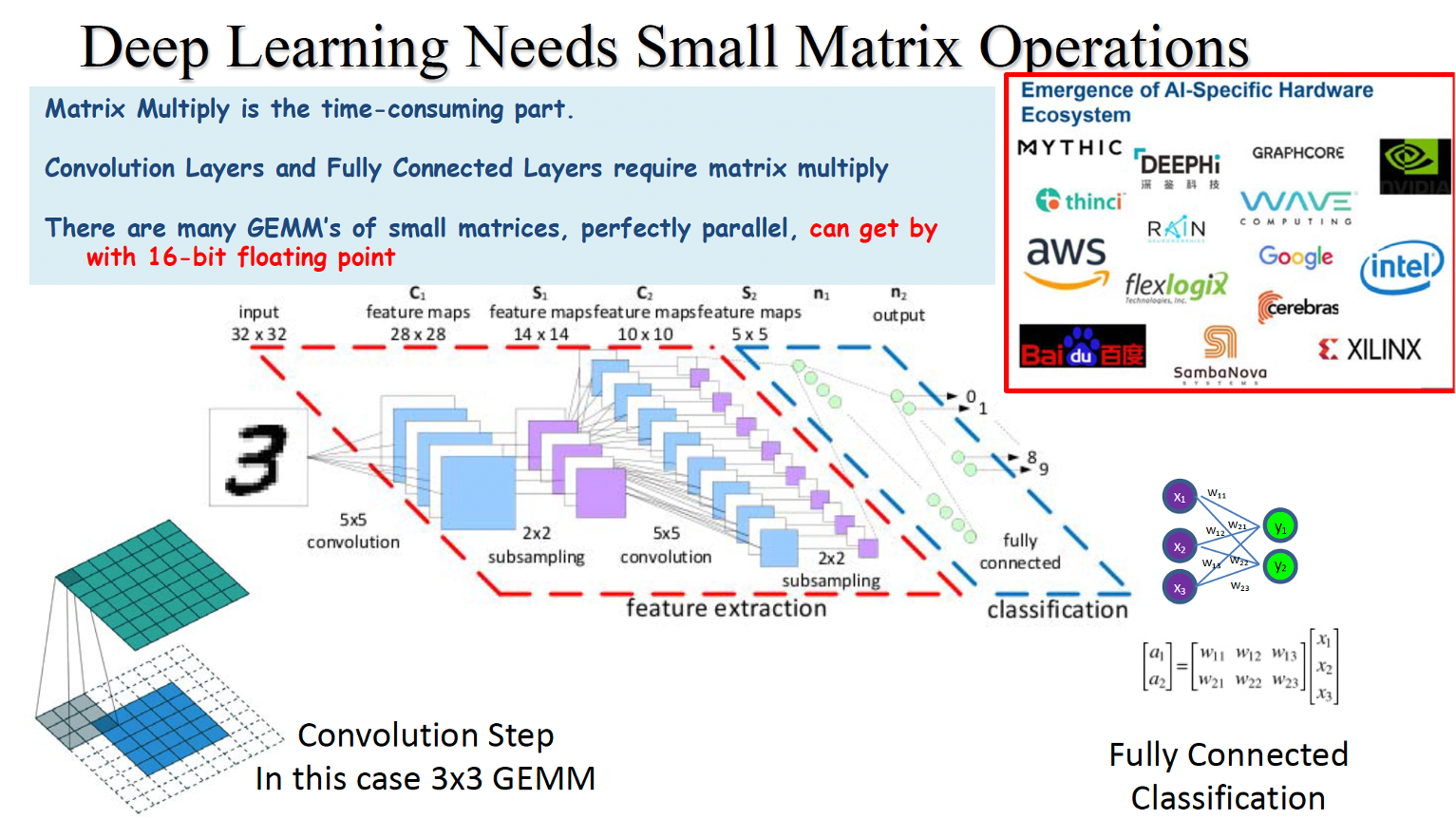
Unlike machine learning models, scientific applications are much more demanding in terms of accuracy but there are early success stories about exploiting a mix of precisions in HPC, including real-time adaptive optics simulations on ground-based telescopes, genome-wide association study for human genomes and agricultural genomics, computational statistics for climate-weather forecasting, and solving inverse problems for seismic processing.
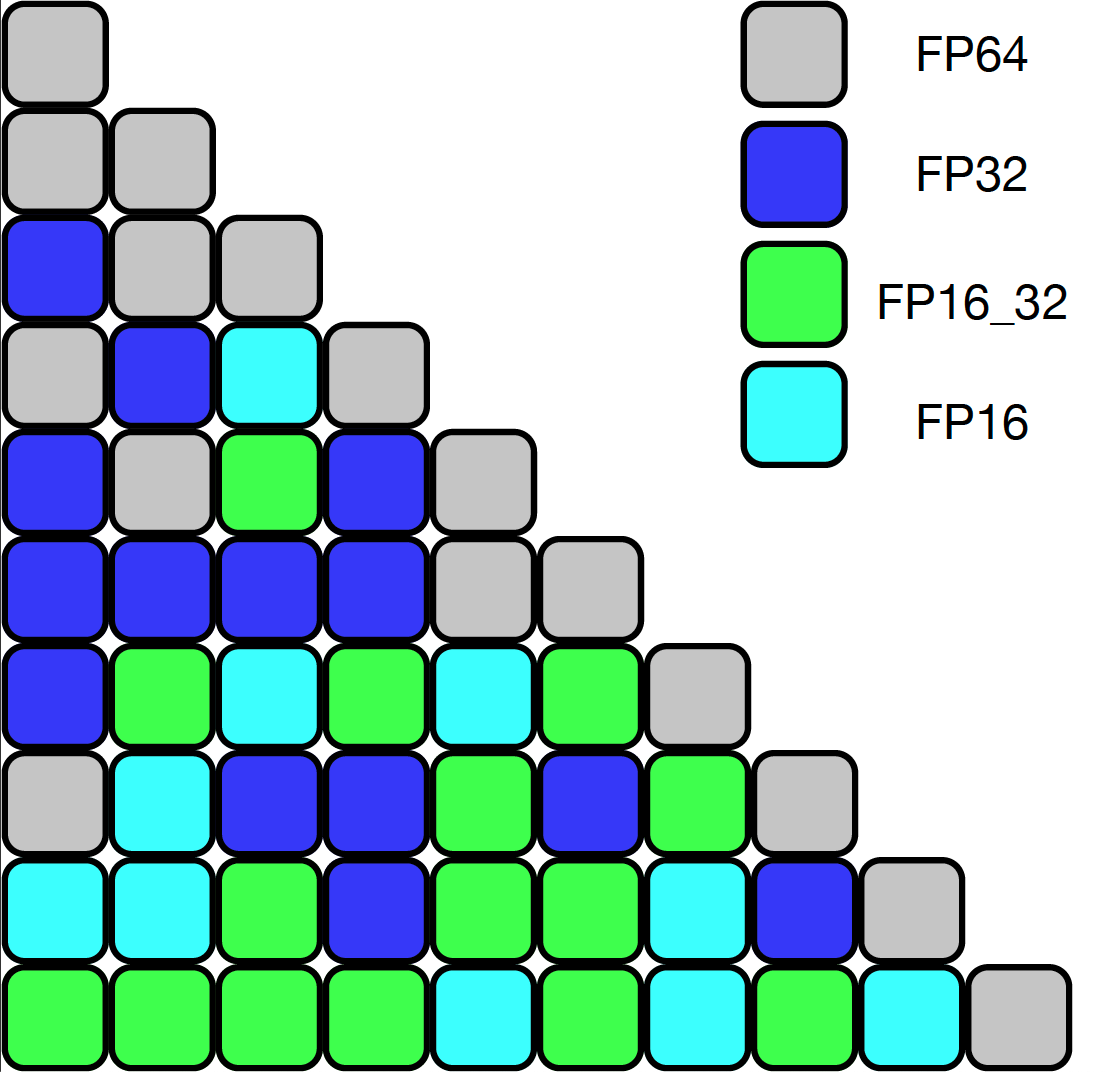
|
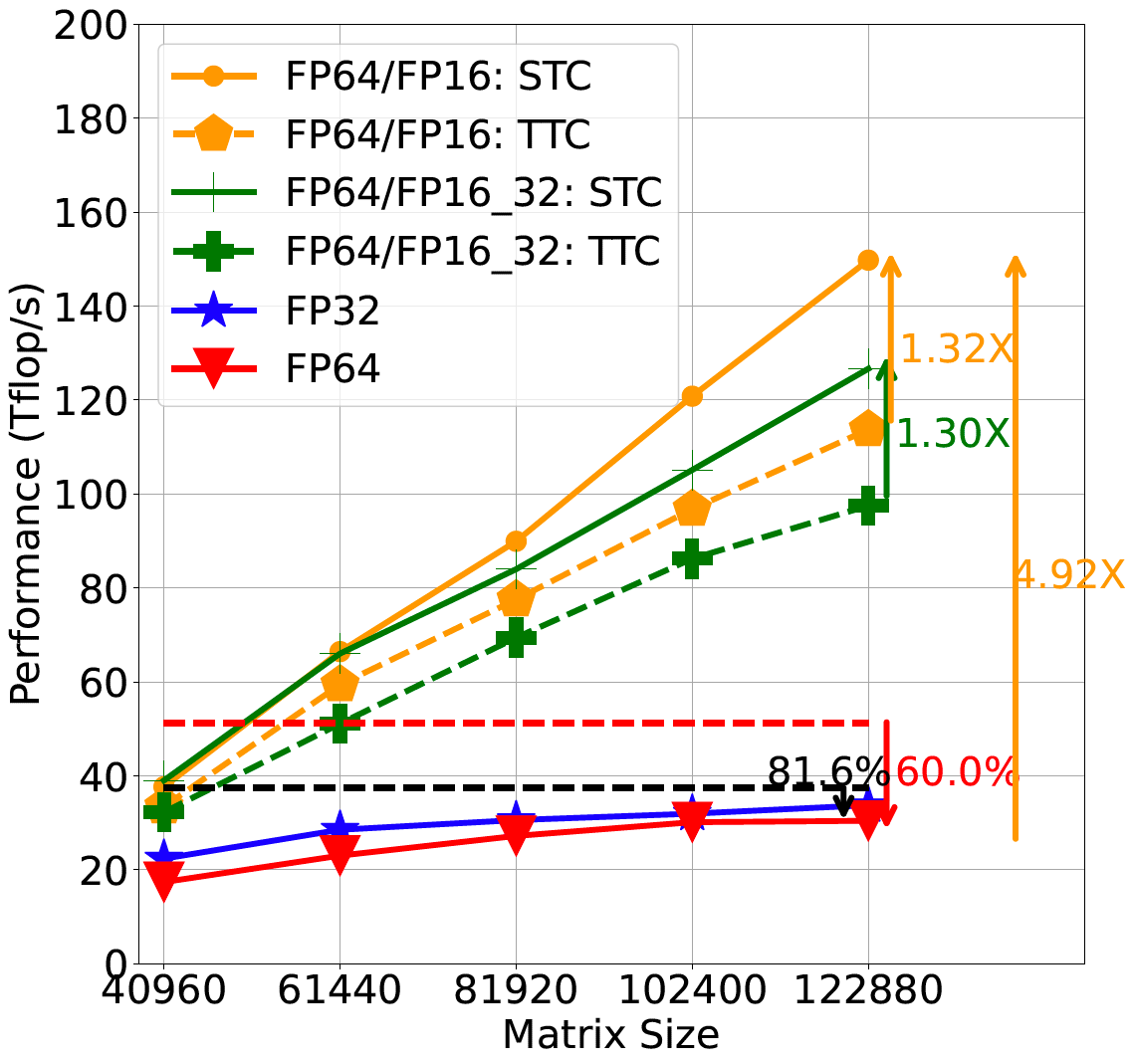
|
| Q. Cao et al., Reducing Data Motion and Energy Consumption of Geospatial Modeling Applications Using Automated Precision Conversion, IEEE Cluster'23. | |
History:
This is the third event of a series on the topic of mixed precisions, which started at SC22, and continued during ISC23. Our previous exchanges with the audience were enriching and permitted to foster the necessary interdisciplinary research collaborations required to address the various computational challenges related to mixed precisions.
Format:
We plan to begin with introductions and a quick round of introductory remarks from the experts and practitioners in the mixed-precision field. These will be focused by driving them with questions and prompts distributed prior to the BoF. Their goal is to lead into the relevant mixed-precision topics but leave enough to explore with clarifying questions from the audience that could steer the discussion towards the specifics of interest. We will follow up with more rounds of prompts towards the invited experts and interaction with the audience to drive the discussion and formulate viewpoints and perspectives that will become the main takeaways of the BoF. The prompt-based interaction will mimic a chat bot session between audience and experts.
We will conclude with the summary of the BoF’s outcomes and explore potential follow-on events while connecting the interest parties for more focused groups engaged in more narrow topics of mixed-precision landscape.
Organizers:
- Hartwig Anzt, Associate Professor and Director, ICL, University of Tennessee Knoxville
- Harun Bayraktar, Director of Engineering, Math and Quantum Computing Libraries, NVIDIA Corporation
- Hatem Ltaief, Principal Research Scientist, ECRC, KAUST
- Piotr Luszczek, Research Assistant Professor, ICL, University of Tennessee Knoxville
SC23 BoF Date, Time and Location:
Tuesday, November 14th 12:15pm-1:15pm
Room 702